|
Сообщения участника "mserg" | |
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Продолжим.
Итак, есть «набор», из которого можно создавать функции отображения матриц. Однако длина этих функций слишком велика, чтобы можно было бы их подобрать.
Эта проблема решается с помощью использования алгоритмов, которые должны за «полиномиальное число шагов» «экспоненциально снизить количество вариантов» при поиске функции. В этом, в сущности, и заключается «информационный» критерий поиска. Вместо «количества информации», для упрощения, будем пользоваться оценкой количества информации (ниже – просто количество информации). Положим, что тип терма функции занимает 8 бит, число – 8 бит, пиксель матрицы изображения – 4 бита, пиксель бинарной матрицы – 1 бит. «Пошаговое» построение отображение функции должно помочь преодолеть комбинаторный барьер.
Рассмотрим задачу, в которой в исходной матрице подсчитывается количество 5-ок, и результатом является пустой прямоугольник высотой 1 и шириной в количество 5-ок. Для определенности положим, что количество 5-к в матрицах имеет 5, 10, 4, 7, 8 (8 относится к тестовой паре). Количество информации, которое потребуется для записи первого результирующего изображения состоит из координаты x – 16 бит, y – 16 бит, ширины и высоты – по 16 бит, пиксели матрицы 5*5*4. Итого 164 бита. Второе результирующее изображение 464 бита, третье – 260, четвертое – 128. Суммарно 1016 бита. Т.к. для тестовой пары результирующее значение неизвестно, что для подсчета количества информации потребуется рассмотреть все возможные размеры матриц.
Использование «tparser.py» приводит к получению прямоугольников для результирующих матриц. Обозначим прямоугольник через rect; (x,y),(w,h) – положение и размер прямоугольника; c – цвет. Описания прямоугольников будут такими:
rect(x=0,y=0,w=5,h=1,c=0), rect(x=0,y=0,w=10,h=1,c=0), rect(x=0,y=0,w=4,h=1,c=0), rect(x=0,y=0,w=7,h=1,c=0)
Сравнение и обобщение структур приводит к функции с одним аргументом:
f(wi) = rect(x=0,y=0,w=wi,h=1,c=0)
Новое описание результирующих изображений будет f(5), f(10), f(4), f(7). Для тестовой пары функция описания будут f(?). Астрономическое количество результирующих матриц свелось к 30 вариантам (допустимы матрицы размером от 1 до 30, насколько я помню).
Количество информации для записи функции состоит из количества информации определения функции f и из количества информации параметров. Определение записи самой функции – 16*2 бита, структура rect – 16 бит, координаты и размеры 16*4, цвет 8+4. Итого, определение функции – 124 бит. Плюс 16*4 – значения параметров, функция описания результирующих (обучающих) матриц сжалось с 1016 бит до 188 бит.
Задача подбора матрицы свелась к задаче подбора одного параметра. Полученная функция, однако, не может быть решением задачи, т.к. аргумент для тестовой пары остается неизвестным.
Простейшие параметры исходного изображения – высота и ширина не подходят. Параметры, получаемые за «1 шаг» из «tparser.py» дадут следующие параметры: комбинации мат. операций над высотой и шириной, минимальный цвет, максимальный цвет, цвет фона (если он есть), максимально частый цвет за исключением фона, гистограмма. Сопоставление с результирующими изображениями приведет к обнаружению, что шестой элемент гистограммы (т.е. с цветом 5), подходит для описания функции. Итого, результирующая функция
res(no, im) = f(hist(im)[5]),
где
f(wi) = rect(x=0,y=0,w=wi,h=1,c=0)
Параметр функции f hist(im)[5] также состоит из 16*4 бит (в ней неявно присутствует функция индекса элемента). Т.е. результирующая функция содержит 188 бит. Если продолжить поиск, то все функции с большим количеством информации должны отсекаться. Если обнаружится функция с меньшим количеством информации – то она заменит текущую (рекорд).
---
Строго говоря, использование пошагового построения функции на основе информационного критерия, не является просто последовательностью. Дерево «перебора функции» все равно неявно присутствует, только поиск ведется более направлено и используемые при поиске структуры – не только древовидные.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 11:10 16.12.2022 |
|
11:13 16.12.2022 |
|
№6055 |
Prosolver:гость 185.220.100:
предлагаю переиначить задачу на более общую и без "побочных эффектов" в виде скрытых ссылок на сложный опыт человека и всей его многомиллионной эволюции. Начать на пример с поворота и сдвига, как это сделать на млп(лесе, цнн и тп) и поразмыслить что может пойти не так Ну хорошо. Поворота и сдвига чего? Я, например, уверен, что начинать надо с выделения объектов. А манипуляции с объектами - это следующий этап. Как можно применить поворот, если ещё нечего поворачивать?
Наиболее общий (пошаговый) критерий решения задач мне все же видится информационный. Выделение объектов - это, по сути, более компактное описание задачи. Оно же - обнаружение информации в задаче. Оно же, в некотором роде, уменьшение размерности задачи. Если принять этот тезис, то выделение объектов и решение всей задачи, это, по сути, одно и то же.
Поворот, зеркало и сдвиг - это аффинные преобразования. Найти задачи можно по ключевым словам rot90, fliplr, flipud в файле manual.py. Есть прямо такие задачи, есть с небольшими дополнениями, есть в составе навороченных задач.
Наборы данных с поворотом, зеркалом и сдвигом, по-видимому, содержат возможности эволюционного решения. Наиболее простые задачи могут быть решены перебором функций. Найденные решения могут обобщаться и перебираться заново. - таким образом "расстояние" от решения одной задачи до решения другой будет находится в досягаемости перебора. Т.е. решений некоторых задач не может быть найдено, пока не найдены решения других, более простых. И, конечно, эти формулы могут использоваться для уменьшения размерности задач.
Технически, для экспериментов, требуется язык (заданный сигнатурой, либо в форме Бекуса-Науэра). Перебор в нем может осуществляться с помощью допустимых правил. Обобщение решения задачи состоит в том, чтобы куски формулы заменять на "свободные переменные" (т.е. разрешить вместо части формулы использовать выражение).
У меня большая просьба. Не нужно мне приписывать желать решать задачи исключительно перебором формул. Не нужно вцепляться в абзац, где написано про перебор - нужно учитывать все написанное, т.к. я не могу делать оговорки в каждом сообщении. Кроме перебора ведь еще говорится и о критерии отбора формул, информационном критерии при поиске, о пошаговом поиске на этом принципе, об иерархии алгоритмов. Выше, например, описана схема проверки возможности эволюции, а не общий метод решения всех задач. |
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Осталось проверить, работают ли чудо-алгоритмы на этом конкурсе
https://www.kaggle.com/competitions/arc-prize-2024/rules
Пока рекорд 38%
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 11:00 28.12.2024 |
|
11:01 28.12.2024 |
|
№11224 |
Лучший результат 53.5% из 100%
https://www.kaggle.com/competitions/arc-prize-2024/leaderboard
Там же есть ссылки на публичные решения справа от результата (в столбике Solution)
Второе место (40%) использует, в частности, парсинг и LLM обучение, понабрав примеры где можно.
Как мне показалось, организаторы соревнования ничего, по большому счету, не получили. И причина уже обозначалась выше - задача разгадки интеллекта на примерах была заменена на стремление решить задачу во что бы то ни стало. И действительно, захожу на сайт организаторов и вижу "We expect to re-launch ARC Prize in Q1 2025. Sign up now to receive official competition updates and news.".
Так что заявление о решении данной задачи несколько преждевременны.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Насколько я понимаю, использование o3-модели не отвечает (не отвечало) требованиям конкурса. Поэтому сейчас конструируют специальную среду, где за рассказы о том, что задачи Шолле решены на 146%, придется платить за использование оборудования. См. https://ARCprize.org . Если будет прогресс на "полу-скрытых" примерах, то будет определенное возмещение расходов.
О возможностях системы o3 разработчики говорят размыто: "While the achievement in ARC-AGI is impressive, it does not yet prove that the code to artificial general intelligence (AGI) has been cracked.". Т.е. если "reasoning models" не будет работать за пределами задач Шолле, то у них будет отмазка (мы не жульничали при решении задач, мы предупреждали, мы не давали обещаний, и т.п.)
Так что пока все в тумане. Есть масса способов для улучшения результатов решения задач Шолле - и парсинг, и генерация примеров, и т.д. Но если скрытые тестовые примеры (точнее алгоритмы генерации) существенно отличаются от обучающих, то обсёр пока представляется довольно вероятным.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Конкурс интересен тем, что ограничено шулерство - есть непубличные тесты. Результат на открытых данных не слишком достоверен.
Открываете и находите o3:
https://arcprize.org/2024-results
на данный момент 82% на публичных данных, 75% на полу-скрытых данных
У o3 нет ссылок ни на код, ни на описания, но есть "comming soon...". Как появится что-нибудь, так и почитаем.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 16:44 29.12.2024 |
|
16:44 29.12.2024 |
|
№11232 |
Вполне могут выложить, т.к. есть признаки неработоспособности:
"While the achievement in ARC-AGI is impressive, it does not yet prove that the code to artificial general intelligence (AGI) has been cracked.".
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
И что тут любопытного? Посмотреть на bruteforce? Так никто не спорит, что можно решить множество тестов грубой силой. Только никому это не интересно.
Вообще-то сам месье Шолле пишет, что o3 толком не работает на его задачах:
https://x.com/fchollet/status/1870170778458828851
И ньюсайнс пишет что по сути ничего нормально не работает:
https://www.newscientist.com/article/2462000-openais-o3-model-aced-a-test-of-ai-reasoning-but-its-still-not-agi/
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Лучше напишите этим дуракам: Mike Knoop, Melanie Mitchell, Chollet, Thomas Dietterich. Пусть ответят за базар:
Цитата:
The o3 model also failed to solve more than 100 visual puzzle tasks, even when OpenAI applied a very large amount of computing power toward the unofficial score, said Mike Knoop, an ARC Challenge organiser at software company Zapier, in a social media post on X.
In a social media post on Bluesky, Melanie Mitchell at the Santa Fe Institute in New Mexico said the following about o3’s progress on the ARC benchmark: “I think solving these tasks by brute-force compute defeats the original purpose”.
“While the new model is very impressive and represents a big milestone on the way towards AGI, I don’t believe this is AGI – there’s still a fair number of very easy [ARC Challenge] tasks that o3 can’t solve,” said Chollet in another X post.
However, Chollet described how we might know when human-level intelligence has been demonstrated by some form of AGI. “You’ll know AGI is here when the exercise of creating tasks that are easy for regular humans but hard for AI becomes simply impossible,” he said in the blog post.
Thomas Dietterich at Oregon State University suggests another way to recognise AGI. “Those architectures claim to include all of the functional components required for human cognition,” he says. “By this measure, the commercial AI systems are missing episodic memory, planning, logical reasoning and, most importantly, meta-cognition.”
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Про "грубую силу" - мопед, действительно, не мой.
На https://arcprize.org/2024-results есть готовые решатели на базе "грубой силы". См. например, решатель от "the ARChitects"
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 11:10 01.01.2025 |
|
12:03 01.01.2025 |
|
№11241 |
Статья по вашей же ссылке называется "OpenAI’s o3 shows remarkable progress on ARC-AGI, sparking debate on AI reasoning".
Там есть раздел, который прямо называется "Not AGI". Там видим следующее:
“Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don’t think o3 is AGI yet,” he writes. “o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.”
Т.е. со слов самого Шолле o3 по факту не работает. Тут дело не в вере или не не в вере конторе openai. Научный подход требует, чтобы проверка проводилась на независимом множестве задач. А признаком независимости в данном случае является такая "логика" задачи, которая, с одной стороны, не встречалась в публичных примерах. А с другой - легко решается человеком. В тестовых непубличных примерах, насколько я понимаю, находятся задачи с разной степенью схожести с публичными задачами. И вот на "несхожих" простых задачах, по видимому, o3 не работает - в этом Шолле и видит проблему. У авторов других цитат, приведенных ранее, появляются одни и те же сомнения, возникших по различным признакам и выраженные в разной формах.
P.S. На счет грубой силы, еще раз, - мопед не мой. Все вопросы к Melanie Mitchell.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Тогда вам нет смысла писать в теме "Решатель ARC-задач Франсуа Шолле".
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 00:39 04.01.2025 |
|
00:40 04.01.2025 |
|
№11249 |
Egg:mserg:
Тогда вам нет смысла писать в теме "Решатель ARC-задач Франсуа Шолле".
Давайте, я сам буду решать есть мне смысл куда-то писать или нет. Вы вот устроили тут истерику на две страницы по поводу того, что о3 это не AGI. Ведь AGI это те и только те системы, которые умеют решать 100% ARC по научному методу. А те системы, которые не AGI не имеют права использоваться для решения интеллектуальных задач. Ведь это золотыми буквами на небесном своде написано. Я люблю изучать поведение людишек)))
Я просто привел мнения из статьи из вашей же ссылки и из других источников. Они выглядят более обоснованно чем ваш "я твой Шолле труба шатал". Т.к. часто ваши сообщения не соответствуют теме - имеет смысл создать другую тему, а здесь часть сообщений удалить.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Спасибо за предложение, но я все же попробую что-нибудь сказать по теме "Решатель ARC-задач Франсуа Шолле".
Итак, ранее я говорил о том, задача сводится к поиску в функциональном пространстве. В большинстве задач Шолле требуется найти вычислимую функцию, отображающую исходные изображения в целевые. Для этого нужно задать сигнатуру - набор функций, их которых будет составляться эта вычислимая функция.
Сигнатура, исходя из данный задачи, должна включать собственно функции (в виде отображения множеств), функция работы с матрицами, рекуррентные и рекурсивные функции, функциональные уравнения, а также работы с графами. Учитывая, что человеческое зрение легко распознает аффинные преобразования, они будут на "особом положении".
Из функций наилучшей считается та, которая корректно отображает обучающие примеры, не "падает" при вычислении тестового изображения, наиболее простая (содержит минимум закорючек)
Стартовать проверку идеи можно с простого переборного алгоритма, который позволяет находить некоторое количество решений.
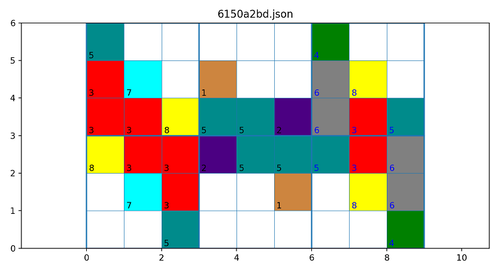
Так на картинке ниже 6150a2bd задача содержит сверху 3 исходных изображения размером 3x3 и 3 снизу целевых также размером 3x3. Цифры черным цветом относят изображения к обучающим примерам, а синим - к тестовым.
Очевидно что задача тривиальная - это аффинное преобразование. Для матричных преобразований можно предполагать использовать функции работы с массивами из библиотеки numpy python. В данном случае это функция rot90. А точнее, rot90(a, 2). Здесь a - исходное изображение, количество закорючек 3 (имя функции и 2 параметра). Хотя, как уже говорилось вместо трех закорючек, аффинные преобразования разумно учитывать особо.
Здесь переборный алгоритм легко находит решение.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
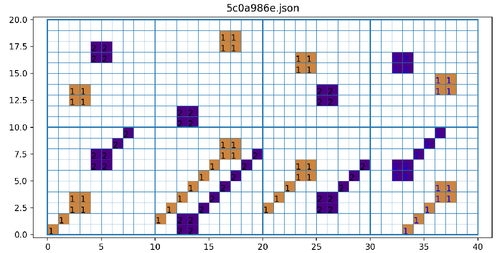
Рекурсивные функции
На приведенной задаче ниже используется рекурсивная функция:
Рекурсивная функция предполагает использование итераций, на каждой из которых используется предыдущее значение аргумента. В данном случае рекурсивная функция должна делать замены
01 на 01
00 10
И
00 на 02
20 20
На каждой итерации будут добавляться единицы и двойки пока изображение не перестанет изменяться.
В данном случае задача отображения матриц превращается в поиске преобразующей функции по окрестностям каждого элемента матрицы (ситуацию с краями опустим для простоты).
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Декомпозиция
Декомпозиция позволяет разбирать изображения на части и сводить задачу к нескольким подзадачам. Так задача ниже может быть легко решена при использовании декомпозиции.
Вместо поиска отображения (или параллельно с оным) можно решать задачу, наиболее кратко описывающие изображения. Так цифры исходные изображения представляют собой множество из двух цифр, одна из которых 0, то изображения могут быть представлены в виде произведения числа (цвета) на булеву матрицу. Функция для вычисления цвета - максимум в матрице; функция вычисления булевой матрицы - преобразование каждого элемента в двоичное значение. Произведение числа на булеву матрицу записывается "меньшим числом бит" нежели исходная матрица. Вместо одного аргумента (исходной матрицы) получаем три: исходная матрицы, ее цвет, и булева матрица. Исходная матрица выглядит лишней в тройке аргументов, однако возможность декомпозиции не редко является подлянкой от Шолле и не упрощает отображение. В этом случае добавление декомпозированных аргументов несколько снижает производительность решателя, но не критично.
Целевые матрицы имеют высоту 1 и содержат только одну цифру (назовем ее тоже цветом). Т.к. высота матрица фиксирована, задача разбивается на две подзадачи: нужно определить длину матрицу и цвет. Решение первой подзадачи (перебором) приводит к формуле, являющейся суммой булевой матрицы из декомпозиции исходной матрицы. Цвет целевой матрицы оказывается равным цвету из декомпозиции исходной матрицы.
Таким образом, задача решилась с относительно небольшим числом шагов перебора.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
| 14:40 05.01.2025 |
|
14:41 05.01.2025 |
|
№11258 |
При использовании указанной выше сигнатуры максимальная глубина поиска количества закорючек в формуле - 5, т.е. если оценка сложности алгоритма подбора функции выше O(n5), то задача не решается. Если, конечно, использовать мощное оборудование, можно нарастить максимальную глубину до 7 или более.
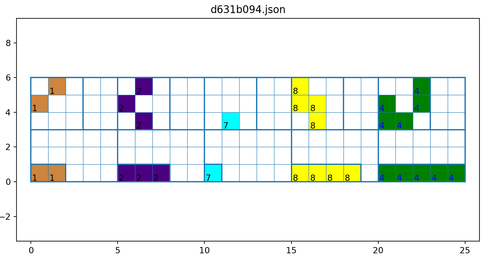
Рассмотрим задачу d631b094. Если выписать действительно "переборное решение", то получим следующее (x-входная матрица)
f(x) = max(x)*sum(bool(x))
Итого 6 закорючек - задача в лоб перебором не решаема.
При использовании декомпозиции исходных изображений имеем
x=max(x)*bool(x)
Т.е. глубина 5 - эта задача решаема перебором.
Получаем три аргумента x, c=max(x), m = bool(x)
При использовании декомпозиции целевых изображений имеем
y=monomatrix(w, 1, e)
Здесь w - ширина матрицы, e - цвет.
Глубина поиска 3 (высота вынуждено равна единице - не является параметром для поиска)
Далее решаем 2 задачи - поиск функции вычисления w в зависимости от x, c, m, и функции вычисления "e" в зависимости от x, c, m. Глубина решения будет будем 2 и 1 соответственно.
С одной стороны, для решения задачи использован перебор. С другой стороны нерешаемая задача решилась. Фокус тут состоит в том, чтобы использовать полиномиальные алгоритмы, которые экспоненциально снижают количество вариантов. Т.е. с ростом "размера задачи" общее число шагов все равно растет экспоненциально, однако основание экспоненты становится меньше.
Возьмем, например, декомпозицию исходных изображений. Подбор функции требует глубины поиска 5:
x=max(x)*bool(x)
Однако, при поиске в ширину используются свободные переменные (обозначим их через знак вопроса). Т.е. функции в ходе поиска могут выглядеть так:
x = max(x)*?
x = ?*bool(x)
Если использовать библиотеку интервального анализа, то x = ?*bool(x) приведет к подзадаче поиска свободной переменной, т.к. для каждой обучающей пары эта переменная будет выявлена как постоянная. Таким образом, выявление формулы декомпозиции x=max(x)*bool(x) потребуется глубина не 5, а 4.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Здесь происходит описание элементов решателя с примерами, а не разбор решения примеров. Народ же хочет понять как происходит мышление - поэтому и приводится разбор примеров, а не просто описание. Описание задачи сводится к системе функционально-алгебраических систем - немного людей, которые это осилят. - поэтому изложение происходит в упрощенной форме, понятное, думаю, большинству.
И, опять же, на данный момент по сведениям https://arcprize.org рекорд на скрытых данных составляет 55.5%, на полускрытых данных - 75.7%. Рекорд на полускрытых данных принадлежит алгоритму o3(tuned), второе место на полускрытых данных составляет 53.6%.
Все возвращается к тому, что o3 не работает так, как openai пытается как бы заявлять. Для того чтобы им поверили, нужно чтобы хорошо работал o3 а не o3(tuned), и демонстрировать результаты на скрытых данных.
Кстати, у нас в конторе, обсуждали эту задачу. У коллег первая же идея была - использование LLM. Но нужно сгенерировать побольше примеров. Можно было, скажем, на Python создать скрипты решения всех обучающих задач, а для генерации использовать рандомизацию каждого из этих скриптов. Далее сгенерировать фигову тучу примеров и обучить в LLM (в ламе, например). В соревновании за 2019 приводились отдельно обучающие, тестовые и оценочные (evaluation - их разработчики могли использовать для локальной проверки при обучении на обучающих данных, и для обучения алгоритма для проверки на тестовых). Анализ примеров предвещал неплохие результаты - значимая часть примеров для проверки имела ту же "формулу" и что и некоторые обучающие примеры, или же близкие к ним. Я им сразу говорил, что такая процедура лишена смысла, т.к. в действительности нужна система, которая способна решать задачи не схожие с обучающими.
Для получения гладкой оценки, скажем, на 100 примерах, "первые" примеры должны иметь максимальную схожесть с обучающими примерами, а "последние" примеры должны иметь "нулевую" схожесть. При этом изменения сложность самих примеров должна быть равномерной по всей шкале от "первых" до "последних" задач. Тогда по мере интеллектуализации решателя, он "гладко" будет увеличивать количество решаемых примеров. Поэтому для тестирования важна не только сложность примеров, но и отличительность их от примеров обучающих. О опять же, все возвращается к неспособности o3 решать простые примеры (со слов Шолле) - тут возникает эффект а ля "утечка данных", что обесценивает результаты.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Egg:
Я вижу другое, вместо того, чтобы показать алгоритм решателя (ARC задачу я ему придумаю сам, чтобы не было утечек)))), Вы что-то очень долго и мутно рассказываете. Алгоритм o1 такие задачи решает, я это проверял и хорошо представляю себе как работает генеративный трансформер. Ваш алгоритм существует только в Ваших рассказах и смутных желаниях))). В этом есть очень большая разница между LLM и какими-то переборами, которые Вы проповедуете.
А что я проповедую? Я говорил, что решение задачи состоит в построении вычислимой функции, которая обладает определенными свойствами: соответствуют обучающим примерам, не валится при вычислении тестовых изображений, и т.д. Я говорил что нужна сигнатура, определяющая "язык" для записи функции (программ). Сигнатура определяет пространство допустимых функций (программ), в которой нужно осуществить поиск. И т.д.
Функциональное пространство суть есть дерево (точнее, DAG), узел которого есть функция (программа). В этом DAG нужно найти наиближайший к корню узел (функцию/программу), которая отвечает нашим требованиям. Вопрос состоит в решении функциональной системы.
А теперь насчет o3, а которой нам никто не расскажет.
Идем сюда https://arcprize.org/blog/oai-o3-pub-breakthrough и читаем раздел "What's different about o3 compared to older models?". И что там насчет сути (т.е. адаптации к новизне)?
Цитата:
To adapt to novelty, you need two things. First, you need knowledge – a set of reusable functions or programs to draw upon. LLMs have more than enough of that. Second, you need the ability to recombine these functions into a brand new program when facing a new task – a program that models the task at hand. Program synthesis. LLMs have long lacked this feature. The o series of models fixes that.
Надо же, "Синтез программ" для новых задач - а не об этом ли я "проповедаю"?. Оказывается для решения ARC-задач требуется "рекомбинация", с помощью которой создаются новые программы, чем суть осуществляется в пространстве функций (программ). Оказывается, как пишут дальше, без этого LLM решает только 5% ARC-задач.
Поиск может происходить регулярным образом, случайным, по эвристике (полученной, скажем, глубоким обучением), и т.п. Игра в слово "перебор" не имеет смысла - он будет все равно, но может быть направленным, усеченным, и т.п.
|
| |
|
write
|
| Решатель ARC-задач Франсуа Шолле |
Egg:
Да, LLM - это алгоритм генерации алгоритмов, это программа создания программ, это система продуцирования систем, я примерно два года об этом рассказываю. Ваше предположение, что можно просто перебором генерировать произвольные алгоритмы, проверять discrepancy и адаптировать путём минимизации ошибки - рано или поздно закончится "изобретением" нейронных сетей как универсального аппроксиматора. Так что Вы на правильном пути.
Прочитайте еще про 13ую проблему Гильберта и теорему Колмогорова-Арнольда. Очень полезно будет.
Тринадцатая проблема Гильберта:
Проблема была решена В. И. Арнольдом совместно с А. Н. Колмогоровым, доказавшими, что любая непрерывная функция любого количества переменных представляется в виде суперпозиции непрерывных функций одной и двух переменных (и, более того, что в таком представлении можно обойтись, в дополнение к непрерывным функциям одной переменной, единственной функцией двух переменных — сложением)
Вот именно это и не работает для ARC задач - "чудо-аппроксиматор" был еще до серии "o".
https://arcprize.org/blog/oai-o3-pub-breakthrough
:
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
А потом Шолле описывает, что нового в серии "o".
Цитата:
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
Речь идет о поиске в пространстве программ, а не о универсальном аппроксиматоре.
Так что кто-то из вас с Шолле не прав. Еще раз - мопед Шолле.
Я могу сказать, что мне не нравится в вашем решении и что Вы пишете.
1. Отсутствуют реальные результаты по решению ARC-задач как с помощью "o1", так и с помощью "o3", Есть результаты по системе, которую Шолле называет "o3(tuned)". "o3" и "o3(tuned)" - это не одно и то же. Проверить "o3" контора openai почему-то не захотела.
2. Задачи нужно не просто решить, а решить эффективно. Результат, на который Вы ссылаетесь (87%), отображен на графике стоимости (см. его по ссылке выше). Цена решения несколько тысяч баксов на одну задачу. Чтобы пройти тесты один раз, нужно истратить сумму, исчисляемую долями от миллиона баксов.
3. Рассказываете то, чего у меня нет. Да есть у меня решатель, он проходить треть от задач первого множества, но он не доделан и тестировать его сейчас смысла нет. Задачи Андрея решаются без проблем, указанные выше мной задачи также решаются. Описания решения задач сделаны по журналу. Там практически все, за исключением мелких деталей, соответствует действительности. Если бы ничего не было, я бы и писать не стал.
P.S. Шолле еще пишет, что у openai будут проблемы на новом множестве задач, - они легче решаются человеком и труднее для систем ai. Его оценка для "o3" на новом множестве - 30%. |
|
|